%20Devum%20Logo.svg "(D) Devum Logo")


Quick Answer: Low-code development platforms fit into an existing enterprise tech stack by operating as a highly extensible orchestration layer rather than an isolated monolith. Modern solutions achieve seamless integration through containerised microservices (Docker/Kubernetes) that permit custom code execution in languages like Java or Python, database-level query optimisation to prevent latency, WebSocket integration for real-time telemetry, and rigorous Centre of Excellence (CoE) governance frameworks that enforce Role-based Access Control (RBAC) to prevent Shadow IT.
The enterprise software architecture landscape is undergoing a systemic evolution, driven by the dual mandates of accelerated digital transformation and the mitigation of crippling technical debt. Historically, engineering teams were forced to choose between rigid, off-the-shelf commercial software and highly bespoke, labour-intensive custom development. However, maintaining legacy systems has become an unsustainable financial burden, with technical debt remediation consuming up to fifteen percent of global IT budgets and resulting in trillions of dollars in annual losses. Concurrently, the global shortage of experienced software developers has severely constrained the ability of IT departments to fulfil the ever-expanding backlog of business unit requests. To bridge this gap, low-code application platforms (LCAPs) have emerged not merely as rapid prototyping tools, but as sophisticated, enterprise-grade orchestration layers capable of seamless integration into complex, pre-existing technology stacks.
This comprehensive analysis deconstructs the architectural mechanics of integrating advanced low-code application platforms, with a specific operational focus on the Devum™ platform into modern enterprise ecosystems. The core insights, real-world friction points, and technical methodologies presented in this guide are directly synthesised from the recent Devum™ Round Table discussions on "How Do Low-code Platforms Fit Into an Existing Enterprise Tech Stack," which brought together software architects, technical directors and enterprise software developers to share their practical integration experiences. The analysis explores the intricacies of microservices extensibility, high-volume data engineering, offline-first edge computing, and the rigorous IT governance frameworks required to prevent Shadow IT in highly regulated environments like banking and logistics.

What Is the Architectural Foundation of a Modern Low-code Platform?
Modern low-code platforms are architected to eliminate boilerplate coding while preserving the logical flexibility required for complex enterprise applications. Rather than operating as isolated silos, platforms like Devum are engineered as comprehensive ecosystems that encompass the entire software development lifecycle, from schema design to infrastructure provisioning and monitoring. Devum, functioning primarily as a ninety percent no-code platform, utilises a simplified pseudo-code language, proprietary termed "DevL", for the remaining ten percent of highly specialised logic that cannot be captured via visual interfaces.
The architecture of such platforms is delineated into several distinct, highly specialised modules that map directly to the traditional Model-View-Controller (MVC) and DevOps paradigms. The operational nerve centre is the Devum Console, an infrastructure management portal where administrators initiate application creation, provision underlying cloud resources, manage deployments, and monitor application health through integrated logging and telemetry.
For the data layer, the platform features a Data Modeller, which serves as a visual schema designer. Database architects and citizen developers alike can structure their data entities and establish complex relational mappings, such as one-to-many or many-to-many relationships, using an intuitive drag-and-drop interface that abstracts the underlying Data Definition Language (DDL) execution. The business logic tier is governed by Domain Services, which enable the creation of "fluent services." These services allow users to visually design intricate backend workflows and algorithmic processes without writing raw server-side code.
On the frontend, the App Studio acts as a highly customisable studio component. It empowers UI/UX designers to construct responsive web and mobile interfaces by assembling pre-configured HTML, Maps, 3D, Form elements and complex widgets. To tie the user interface to backend processes, the Workflow Builder and KPI Builder facilitate the automation of business processes and the generation of analytical dashboards, respectively. Furthermore, the inclusion of an integrated AI development bot, Dev Bot assists developers by building a foundational schema and app pages to start with during the build phase.
Table 1 provides a comparative overview of how traditional development layers translate into modern low-code platform modules.
Table 1. Overview of traditional development layers to their corresponding modules in a modern low-code platform
How Do Low-code Microservices Integrate Custom Code Without Breaking Platform Governance?
A persistent and historically valid critique of early low-code solutions was the risk of vendor lock-in and the inability to execute complex, proprietary algorithms that fell outside the platform's visual capabilities. Modern enterprise platforms like Devum™ have resolved this constraint by adopting a microservices-based architecture that natively supports traditional high-code extensibility.
When complex industrial requirements dictate logic that is too intricate for visual builders, such as proprietary geolocational parsing, advanced cryptographic hashing, or custom CAD file conversions, developers are not forced to abandon the low-code environment. Instead, platforms like Devum™ provide a Microservices Software Development Kit (SDK) that allows software engineers to author custom functions in enterprise-standard programming languages, including Java, Scala, and Python.
This hybrid capability is underpinned by containerisation technologies. Custom code is compiled and encapsulated within isolated Docker containers, which are subsequently orchestrated by a Kubernetes cluster. This containerised approach yields profound architectural benefits. Primarily, it establishes strict fault isolation. If a custom Python script contains a memory leak, an infinite loop, or a fatal exception, the failure is strictly contained within its specific Docker container. The core low-code platform and the broader application remain fully operational, preventing a localised code defect from cascading into a systemic outage.
Furthermore, this architecture enables granular, independent scalability. A microservice responsible for heavy computational tasks can be scaled horizontally across the Kubernetes cluster independently of the lightweight user interface components, optimising cloud resource utilisation and cost. The integration of these custom microservices back into the low-code environment is seamless. Once a Docker container is registered within the platform's console, the custom function appears within the visual builder's library. Citizen developers can then drag and drop the custom Java or Python function into their workflow just as they would a native component, entirely unaware of the underlying containerised complexity.
Why Do Function Calls Inside List Filters Cause Application Latency?
While low-code application platforms significantly accelerate application delivery, the abstraction of underlying execution environments can inadvertently mask highly inefficient query designs. A critical performance bottleneck frequently encountered by developers transitioning to low-code application platforms involves the misuse of server-side function calls within list filtering operations.
In visual development environments, engineers routinely utilise "list filter" components to isolate a specific subset of elements from a broader dataset. The performance degradation occurs when a developer embeds a dynamic function call, such as a complex calculation, a string manipulation, or an external API request, directly within the filtering condition.
When a function is placed inside a filter loop, it forces the application server into a synchronous, blocking execution pattern. The server must pause the evaluation of the list, execute the nested function for the current row, await the response, and only then proceed to the next row. From a computer science perspective, this transforms what should be a highly optimised, set-based database operation into an O (N) iterative process executed at the application layer. As the volume of data grows, this synchronous waiting introduces severe network latency and noticeable user interface lag.
The engineered solution to this latency requires a shift toward declarative filtering utilising static entity attributes. Rather than dynamically calculating values during the filter loop, developers must ensure that the filter evaluates exclusively against static, pre-calculated fields or direct identifiers, such as an employee_ID. By restricting the list filter to static attributes, the low-code development platform's compiler can seamlessly translate the visual logic into an optimised SQL WHERE clause. This architectural refinement facilitates "predicate pushdown," allowing the underlying database engine to utilise its native indexing structures to retrieve the exact subset of data efficiently, thereby bypassing the application-layer processing bottleneck entirely.
Table 2 delineates the performance implications of procedural versus declarative filtering in low-code environments.
Table 2. Comparison of procedural and declarative filtering in low-code environments
How Can Low-Code Applications Handle High Volume Data and Real-time Telemetry?
Enterprise low-code applications built on modern platforms like Devum™ are frequently deployed in operational environments that generate massive streams of real-time telemetry. Managing, processing, and visualising this data without overwhelming the client-side architecture requires sophisticated performance engineering and strategic data handling protocols.
Data Sampling and Cognitive Load Management
Consider an industrial deployment within an underground mining operation. The low-code application is responsible for monitoring ambient gas levels, tracking the movement of subterranean personnel, and controlling vehicular traffic flow across various ramps. The hardware sensors in this environment may ingest data at an aggressive frequency, transmitting updates every five milliseconds.
Attempting to render every single data point from a thirty-day historical period onto a user interface dashboard is a fundamental architectural error. Transmitting millions of records to a web browser inevitably overloads the Document Object Model (DOM), consumes excessive client-side memory, and causes the JavaScript execution thread to freeze. Furthermore, presenting data at this granularity creates severe "data fatigue" for the human operator, rendering the dashboard analytically useless.
To resolve this, engineers must implement data sampling and interval visualisation strategies. Instead of pushing the raw, millisecond-level telemetry to the frontend, the backend microservices aggregate and sample the data at fixed, logically significant intervals, such as taking a single data point every ten, twenty, or fifty seconds. This drastically reduces the network payload while preserving the statistical integrity of the trends required for decision-making.
Additionally, when rendering extensive historical records or complex 3D studio visualisations of the mine's geo-coordinates, the application must utilise UI virtualisation. UI virtualisation strictly limits the memory footprint, often capping it at a threshold like one hundred megabytes by dynamically recycling DOM elements. As the user scrolls through a time-series historical playback, only the data actively visible within the viewport is rendered, while subsequent chunks of data are fetched asynchronously.
Polling Versus WebSockets for Real-time Synchronisation
Beyond historical data visualisation, low-code platforms must frequently synchronise real-time state changes between the database and concurrent users. This is particularly critical in systems managing scarce, highly contested resources.
For instance, an enterprise low-code application deployed for an automated parking facility must track physical barrier controls, proximity sensors, and available parking capacity. If a user interface displays an available parking space, but a physical vehicle triggers a sensor to occupy that space, the application must immediately update all active client dashboards to reflect the change and prevent double-booking.
Historically, developers relied on HTTP short polling to achieve this. The client application would send repeated API requests to the server every few hundred milliseconds, querying if the parking state had changed. This methodology is highly inefficient, as each request requires a full TCP handshake and database query execution, rapidly exhausting server connection pools even when no data has changed.
Advanced low-code architectures like Devum™ solve this concurrency challenge through the native implementation of WebSockets. A WebSocket establishes a persistent, full-duplex communication channel over a single TCP connection. Following the initial handshake, the connection remains open, allowing the server to autonomously push data payloads directly to the client the exact millisecond a database state change occurs. This eliminates the overhead of continuous polling, drastically reduces server load, and ensures absolute real-time accuracy across all integrated user interfaces.
What are the Best Practices for Offline-first Architecture in Industrial Low-code Apps?
While cloud-native architectures assume persistent internet connectivity, many critical enterprise deployments operate in environments where connectivity is intermittent or entirely absent. Industrial use cases, maritime logistics, and surface as well as deep underground mining operations necessitate that low-code applications be engineered with robust offline-first capabilities.
In scenarios where standard internet access is unavailable, organisations deploy localised mesh networks. These networks utilise strategically positioned hardware anchors to create a closed intranet, allowing devices within the operational zone to communicate with local servers even if the external connection is severed. The low-code application running on a mobile device or ruggedised tablet must be capable of fully functioning within this disconnected state.
To achieve this, the application architecture leverages local storage mechanisms, such as SQLite databases or encrypted file systems on the device to cache transactional data. When an operator logs a maintenance action, records a gas sensor anomaly, or updates a logistical manifest, the application writes this data to the local cache. The system actively monitors the network interface; upon detecting the restoration of connectivity to the central server, an automated background synchronisation service initiates.
This synchronisation protocol must be governed by strict rules. The platform must execute conflict resolution algorithms to determine the chronological hierarchy of data, ensuring that offline actions do not inadvertently overwrite more recent authoritative data entered by users who maintained connectivity. By embedding these offline caching and synchronisation mechanics directly into the platform's framework, low-code providers eliminate the need for enterprise developers to manually engineer complex offline state-management logic.

How do Enterprises Prevent Shadow IT and Enforce Low-code Governance?
The defining value proposition of low-code platforms is the democratisation of software development. By empowering "citizen developers", business analysts, marketing professionals, and operations managers, to construct applications without writing raw code, organisations can bypass the traditional IT backlog. However, this democratisation introduces profound risks. Unregulated application development leads directly to "Shadow IT," resulting in duplicated functionality, severe security vulnerabilities, data privacy breaches, and unmaintainable system architectures.
To harness the speed of low-code development while maintaining rigorous enterprise security, organisations must institutionalise a Centre of Excellence (CoE) and deploy strict IT governance frameworks. The CoE functions as the central governing authority, tasked with defining architectural standards, managing API endpoints, auditing security compliance, and maintaining a repository of approved, reusable low-code components.
The "Learner's License" and Role-based Access Control
In highly regulated environments, such as global financial institutions citizen developers are never granted autonomous deployment privileges. Instead, governance models employ a "Learner's License" paradigm. Under this framework, a citizen developer is permitted to visually design the application's workflow and user interface, but they are permanently paired with a credentialed IT professional from the CoE. This IT counterpart reviews the underlying logic, optimises data queries, and officially authorises the deployment to production, ensuring that business agility is always counterbalanced by technical oversight.
Platform-level security features are critical to enforcing this governance. Enterprise low-code environments must support advanced Role-based Access Control (RBAC) and seamlessly integrate with organisational Single Sign-On (SSO) identity providers. This access control extends beyond simple application entry; administrators must be able to define permissions at the granular component level. For instance, using unique CSS or ID tags, the platform can dictate that a specific approval button or sensitive data grid is only visible and actionable by users holding a specific managerial clearance.
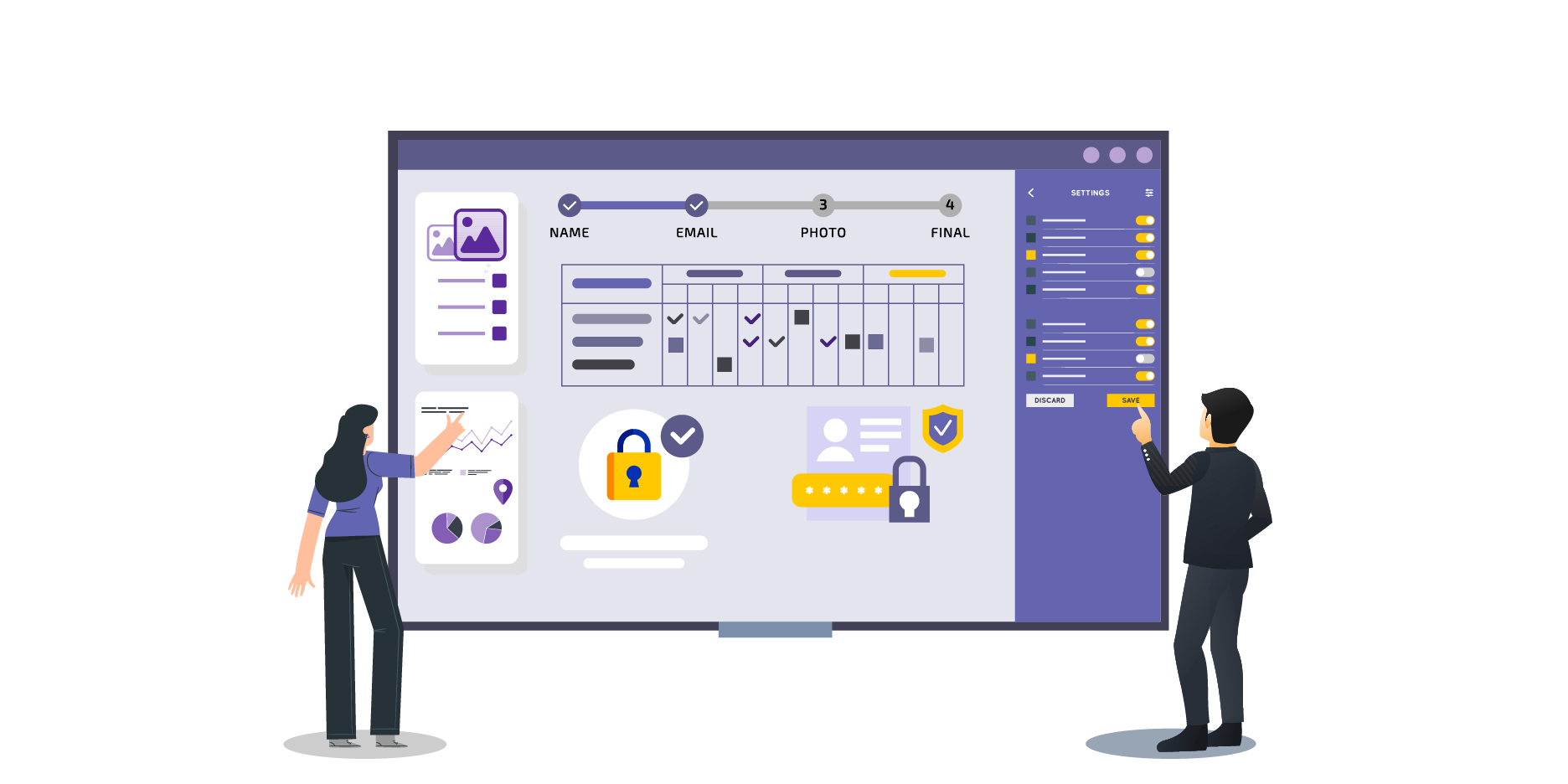
Automated Security Analysis and Penetration Testing
The transition of an application from a development environment to production must be gated by comprehensive security analyses. Although low-code platforms abstract the coding process, the visual models ultimately compile down to standard application code that can harbour vulnerabilities.
Enterprise governance pipelines mandate the integration of Static Application Security Testing (SAST) tools. These tools automatically parse the underlying codebase to detect insecure configurations, hardcoded credentials, and architectural anti-patterns before the software is compiled. Following successful static analysis, Dynamic Application Security Testing (DAST) is utilised to simulate runtime attacks against the operational application, identifying vulnerabilities such as cross-site scripting or SQL injection.
Furthermore, major enterprise releases require manual penetration testing. Security analysts review the automated reports and conduct targeted attacks to uncover complex logical flaws that automated scanners inherently miss. Any application that fails these rigorous security gates is automatically blocked from deployment until the citizen developer and their CoE counterpart remediate the identified risks. This "shift-left" security posture ensures that vulnerabilities are addressed during the development lifecycle rather than after a production breach.
Table 3 categorises the layers of governance required for secure enterprise low-code adoption
Table 3. Governance layers for secure enterprise low-code adoption
Synthesis: Architecting for Agility and Governance
The The modern enterprise technology stack is defined by its demand for unparalleled agility and uncompromising governance. The historical reliance on high-code monoliths is no longer viable in an era characterised by rapid digital transformation and severe developer shortages. Low-code application platforms provide the necessary abstraction to accelerate delivery, but their successful integration requires rigorous architectural discipline.
Engineering teams must master the nuances of the Strangler Fig pattern to seamlessly modernise legacy infrastructure without incurring operational downtime. They must leverage containerised microservices to execute complex algorithmic logic without violating the fault isolation of the low-code environment. Furthermore, overcoming the inherent performance challenges of high-volume data requires a shift from procedural application-layer filtering to database-level predicate pushdown, the enforcement of UI virtualisation, and the adoption of persistent WebSockets to replace inefficient HTTP polling. Crucially, the democratisation of development must be secured by a Centre of Excellence, enforcing strict Role-based Access Controls and automated security testing to eliminate the existential threat of Shadow IT. Ultimately, the enterprises that will dominate the next technological epoch are those that seamlessly fuse the rapid execution of low-code architectures with uncompromising technical oversight.
Start your journey with Devum™ today. Sign up and build your first application.
👉 Subscribe to Devum™: https://Try.Devum.com/#/security/SignUp


